Publications
PhD Thesis
Deep Cross-Modal Alignment in Audio-Visual Speech Recognition
http://www.tara.tcd.ie/handle/2262/96649
Journal publications
George Sterpu, Christian Saam, Naomi Harte. How to Teach DNNs to Pay Attention to the Visual Modality in Speech Recognition.
IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020.
pdf
IEEE XploreGeorge Sterpu, Naomi Harte. Taris: An online speech recognition framework with sequence to sequence neural networks for both audio-only and audio-visual speech.
Elsevier Computer Speech & Language, 2022.
Open Access
Conference articles
George Sterpu, Christian Saam, Naomi Harte. Learning to Count Words in Fluent Speech enables Online Speech Recognition
IEEE Spoken Language Technology Workshop (SLT 2021).
arXiv
codeGeorge Sterpu, Christian Saam, Naomi Harte. Should we hard-code the recurrence concept or learn it instead ? Exploring the Transformer architecture for Audio-Visual Speech Recognition
Interspeech 2020.
arXiv
codeGeorge Sterpu, Christian Saam, Naomi Harte. Attention-based Audio-Visual Fusion for Robust Automatic Speech Recognition
2018 International Conference on Multimodal Interaction (ICMI 2018).
Boulder, CO, USA, October 2018.
arXiv
code
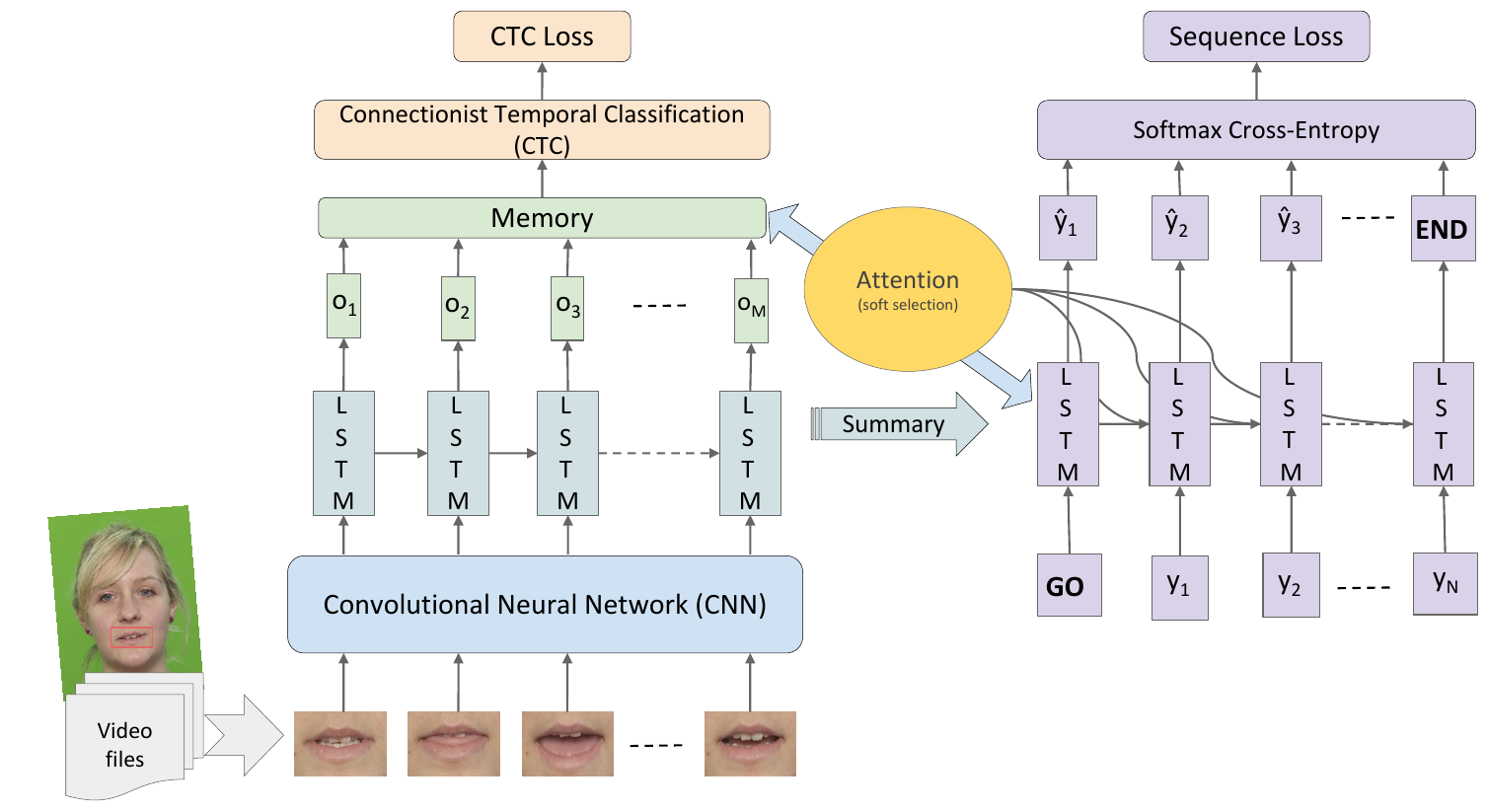
diagramGeorge Sterpu, Christian Saam, Naomi Harte. Can DNNs Learn to Lipread Full Sentences?
The 2018 IEEE International Conference on Image Processing (ICIP 2018).
Athens, Greece, October 2018.
arXiv
code
diagramGeorge Sterpu and Naomi Harte. Towards Lipreading Sentences using Active Appearance Models
International Conference on Auditory-Visual Speech Processing (AVSP 2017).
Stockholm, Sweden, August 2017.
arXiv
code
{kind=link}